🇫🇷 FCSC | DisplayPort ⭐⭐⭐
Table of Contents
Hardware: Display Port ⭐⭐⭐

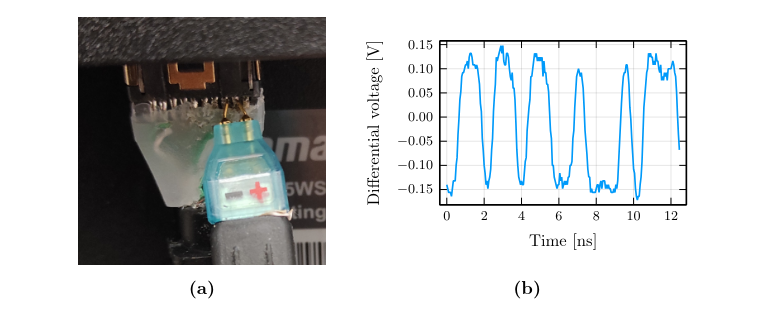
Ce challenge nous présente le résultat d’une capture décodée du signal différentiel entre les pin #1 et #3
On a pas mal d’informations à propos de la norme, des dimensions et des caractéristiques de l’écran, tout ne va pas nous servir tout de suite. Il faut y aller pas à pas.
Une 1ere recherche rapide sur Wikipédia nous apprend que les pin 1 et 3 correspondent aux données transmises par la ligne 0 sur les 3 lignes correspondantes. Notre “.bin” correspond donc aux données transmises par une seule et même ligne. La complexité du challenge va résider dans le désencapsulage de chaque couche pour pouvoir décoder les données.
La pêche aux informations 🎣
Maintenant que nous savons de quoi il s’agit, il va falloir trouver les informations sur displayport 1.2 les plus digestes possibles et les plus compréhensibles, je dois décoder une seule fois le tout, pas créer un driver fonctionnel compatible displayport 1.2.
Après avoir creusé profondément internet en recherche de documentation, j’ai en ma possession:
- Une Présentation PPT du protocole displayport (?)
- Les standards displayport de 2010 (?)
- Et surtout une thèse d’un étudiant de Cambridge qui a fait exactement la même chose (?)
Les différentes couches de DisplayPort
Dans le chapitre 3 de la thèse (p45) on nous présente comment retrouver l’image à partir de trames capturées sur la ligne 0 de displayport, nous avons même le droit à une photo ressemblant grandement à ce qui est proposé dans l’énoncé :
S’il y a bien un schéma sur lequel j’ai pu m’appuyer, c’est celui-ci :
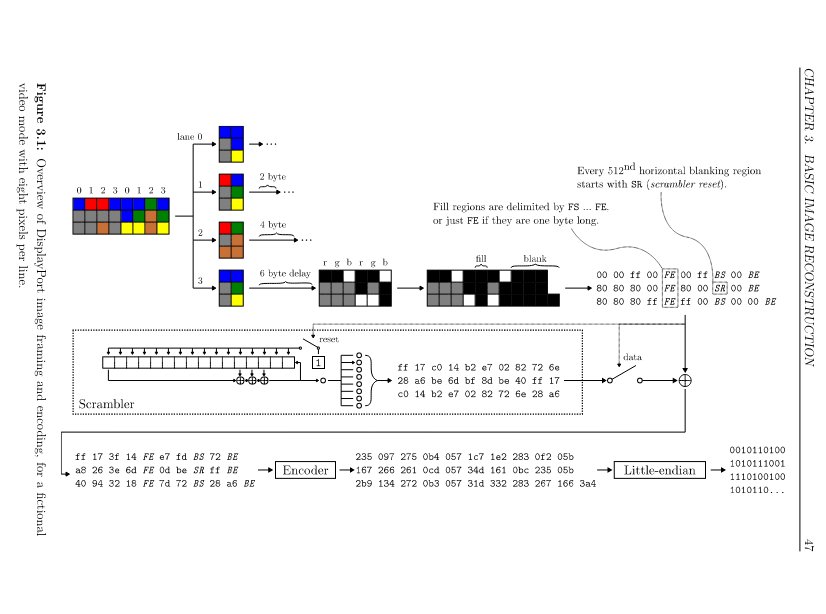
Il est clair, il nous fournit des exemples et c’est encore une fois exactement ce en quoi consiste le challenge.
Comme chaque protocole, DisplayPort comporte des “layers”, les données sont encapsulées sous différentes couches.
Pour résumer:
- “Framing” des pixels dans des trames avec des symboles spéciaux appellés symboles de contrôles, pour dire quand commence les données, quand finissent les données, quand commence le “padding”, etc.
- “Scrambling” des données dans les trames en xorant chaque octet de donnée avec un générateur d’entropie standard (LFSR)
- Encodage de chaque octet en 8b10b
Nous avons le résultat final, les données codées en 8b10b, c’est un encodage pour étendre des octets, ça sert notamment au protocole DisplayPort pour faire la différence entre des octets qui correspondent à des pixels et des octets qui sont des codes de contrôle.
C’est parti pour remonter chaque couche jusqu’au décodage final de l’image.
Décodage
Mon 1er réflexe a été d’aller trouver une bibliothèque qui pourrait m’aider à décoder mes données en blocs de 10 bits en un flux d’octet avec les emplacements des codes de contrôles enregistrés.
En python nous avons encdec8b10b que je vais utiliser dans un 1er temps.
NOTE: Dans l’énoncé, on nous dit
“J’ai enregistré ces bits dans un fichier binaire, au format suivant : 8 bits par octet, le bit de poids fort étant le premier bit transmit (MSB first).”
Cette formulation a été un peu déroutante pour moi. En fait c’est simplement que chaque bit décodé du signal analogique converti a été enregistré dans le fichier au “goute à goute”, Ainsi le fichier qui commence par “52 3d” donne “01010010 00111101” en binaire, nous on va en faire des paquets de 10 bits sans pour autant toucher au sens, donc on va lire “0101001000 111101..”
Mon 1er essai consistait à regarder comment le décodage des données se faisait :
from encdec8b10b import EncDec8B10B
def read_bits_from_file(filename, bit_offset=0):
with open(filename, "rb") as f:
data = f.read(75)
bitstream = []
for byte in data:
for i in reversed(range(8)):
bitstream.append((byte >> i) & 1)
bitstream = bitstream[bit_offset:]
return bitstream
def get_10b_blocks(bitstream):
blocks = []
for i in range(0, len(bitstream) - 9, 10):
block = bitstream[i:i+10]
if len(block) == 10:
blocks.append(block)
return blocks
if __name__ == "__main__":
import sys
filename = sys.argv[1]
offset = int(sys.argv[2]) if len(sys.argv) > 2 else 0
dec = EncDec8B10B()
bitstream = read_bits_from_file(filename, bit_offset=offset)
blocks = get_10b_blocks(bitstream)
print(f"{len(blocks)} blocks, offset: {offset} bits.")
for i, block in enumerate(blocks[:60]):
print(f"{i:04d}: {''.join(map(str, block))}", end=" ")
try:
print(dec.dec_8b10b(int(''.join(map(str, block)), 2)))
except:
print("False")
Normalement je ne devrais pas avoir trop de “False”, qui correspondent à des erreurs de dec_8b10b. On peut accorder le bénéfice du doute si très peu de symboles de 10 bits sont concernés, mais nous devrions quand même avoir un flux correct. Donc trop de “False” indique sûrement dans mon cas que le pointeur de données n’est pas synchronisé avec le flux du display port, en posant la sonde ou en démarrant le logiciel si l’écran est déjà démarré et reçoit des flux de données, nous pouvons très bien avoir un décalage.
Il nous suffit donc de tester plusieurs décalages et voir si l’un des décalages nous donne largement moins de “False” que les autres. Pour tester efficacement, je ne lis que 600 bits et j’affiche le résultat des 60 premiers octets décodés.
Le 1er nous donne environ 15 “False” pour un échantillon de 60, c’est beaucoup trop. Pareil pour le 2eme, le 3eme, le 4eme, mais le 5eme ne nous donne aucun “False”, Bingo ! On aurait trouvé le bon alignement ?
J’étends mon script pour calculer l’entièreté de la capture et calculer le taux d’erreur en %
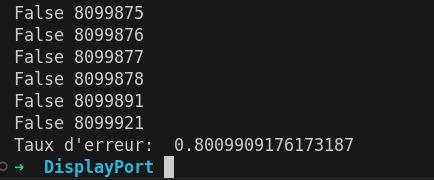
On a bien un taux d’erreur inférieur à 1%, tandit que tous les autres candidats ont environ ~15% de taux d’erreur, je lui accorde le bénéfice du doute.
Sauf que quelque chose ne va pas.
En plus qu’aucun code de contrôle trouvé ne corresponde à la spécification DisplayPort, l’occurrence du symbole “SR” (Scrambler Reset) devrait correspondre à ~512x moins que le symbole “BS”, (on retrouve le “SR” tous les 512 “BS”).

À partir de là j’ai cherché dans beaucoup de directions.
Après avoir fixé une bête erreur de parsing des données binaires. Je ne retrouve toujours pas mes données correctes. Du moins, que j’estime correctes.
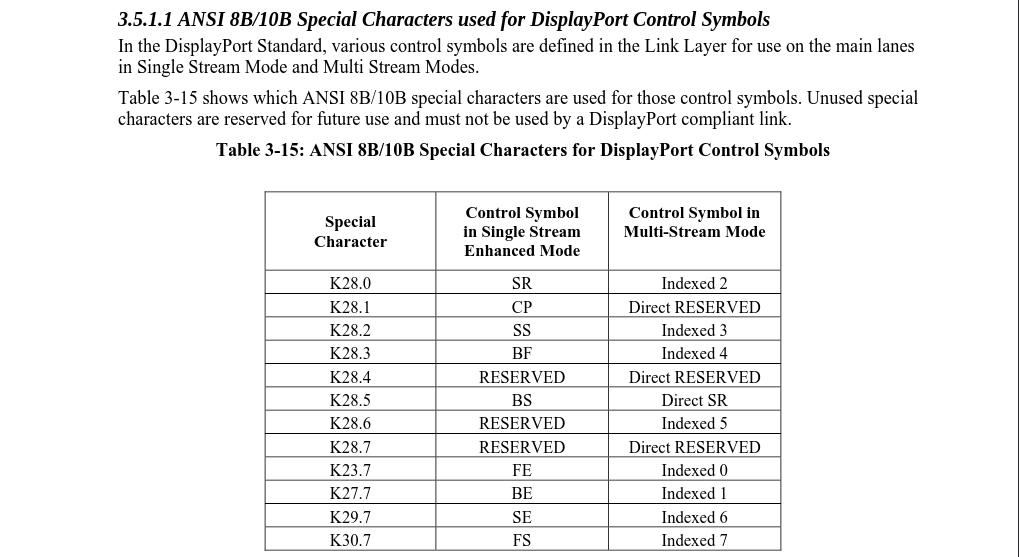
C’est les spécifications d’USB 3.1 qui m’ont étonnamment aidée, l’encodage des données semble être le même, je l’ai trouvé en dorkant les constantes de SR (K8.0) (001111 0100) et BS (K28.5) (001111 1010). (Il se trouve derrière un loginwall, il se trouve ici)
Au lieu d’utiliser encdec8b10b je vais utiliser la table “Gen 1 Symbol Encoding” de la spécification (p585) :

On a d’ailleurs la valeur 10 bit dans les deux sens, ça rajoute une sécurité en plus. Voici la nouvelle table :
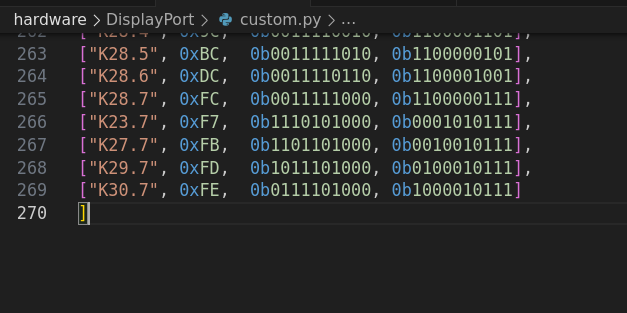
Et maintenant bingo !!! (pour de vrai cette fois) à l’offset 9 on a un taux d’erreur à 0% (contre ~15% des autres). Et on a SR = BS/467.

Cette fois c’est sûr, on a mis le doigt sur les données.
(On retrouve la relation caractère spécial:symbole de contrôle dans la spécification displayport 1.2) (p353)
Voici le code qui décode correctement mes données :
import numpy as np
from custom import custom # ma liste custom
def bytes_to_bit_chunks(byte_data, chunk_size=10, offset=0):
arr = np.frombuffer(byte_data, dtype=np.uint8)
bits = np.unpackbits(arr)
if offset >= len(bits):
return []
bits = bits[offset:]
total_bits = len(bits)
usable_bits = (total_bits // chunk_size) * chunk_size
bits = bits[:usable_bits]
chunked_bits = bits.reshape((-1, chunk_size))
return chunked_bits.tolist()
def read_bits_from_file(filename=None, offset=0):
with open(filename, "rb") as f:
data = f.read()
arr = bytes_to_bit_chunks(data, 10, offset)
return arr
def search_for_line(elm, array):
for e in array:
if(elm == e[-1] or elm == e[-2]):
return e[0], e[1]
return None
if __name__ == "__main__":
import sys
if len(sys.argv) < 2:
print("python.py fichier.bin [offset_bits]")
sys.exit(1)
filename = sys.argv[1]
offset = int(sys.argv[2]) if len(sys.argv) > 2 else 0
bitlist = read_bits_from_file(filename, offset)
arr_cntrl = []
arr_bytes= []
err = 0
t = {}
bi = 0
for i, block in enumerate(bitlist):
binrepr = "".join([chr(x+0x30) for x in block])
r = search_for_line(int(binrepr, 2), custom)
# print(dec.dec_8b10b(int(binrepr, 2)))
if(r != None):
if(r[0][0] == "K"):
if r[0] not in t:
t[r[0]] = 1
else:
t[r[0]] +=1
arr_cntrl.append((1, r[1]))
else:
arr_cntrl.append((0, r[1]))
arr_bytes.append(r[1])
else:
err+=1
bi+=1
with open("decoded.bin", "wb") as f:
f.write(bytes(arr_bytes)) # pour encore plus de tests sur les données
with open("cntrl.py", "w") as f:
f.write("flux =[")
f.write(",".join([str(x) for x in arr_cntrl]))
f.write("]")
print([k+" : "+str(v) for (k, v) in t.items()])
print("Taux d'erreur: ", err/bi*100)
# K28.0 SR 1c
# K28.1 CP 3c
# K28.2 SS 5c
# K28.3 BF 7c
# K28.5 BS bc
# K23.7 FE f7
# K27.7 BE fb
# K29.7 SE fd
# K30.7 FS fe
J’ai fait le choix de sauvegarder les données décodées dans un fichier python qui contiendra un très grand tableau de tuple (contrôle: bool, octet: int) Le parsing sera long au 1er lancement du décodeur, mais mon extension python sur Vscode cache les tableaux une fois décodés pour la 1ere fois, donc tous les lancements ensuite seront quasiment instantanés.
Unscrambling
“To flatten the frequency spectrum of electromagnetic interference generated, link data is scrambled using a maximum-length 16-bit linear-feedback shift register (LFSR) defined by the polynomial x16 + x5 + x4 + x3 + 1” (p51 de la thèse)
Cette fois, pas question d’utiliser une librairie python sans réfléchir.
Dans un premier temps on nous a donné un exemple de à quoi devrait ressembler les premiers octets générés par le LFSR.
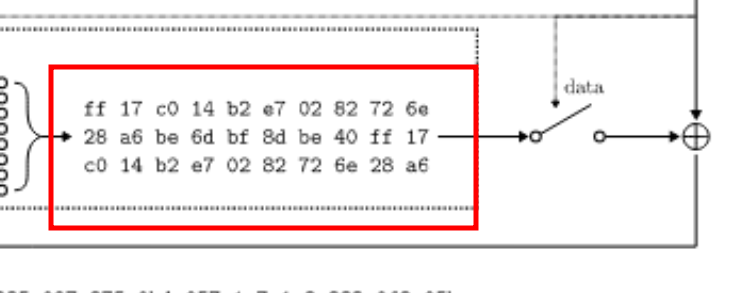
L’objectif va être simple, retrouver l’implémentation et faire un générateur en python.
Et bien, c’est encore sur les spécifications d’USB3.1 qu’on retrouve le même scrambler :
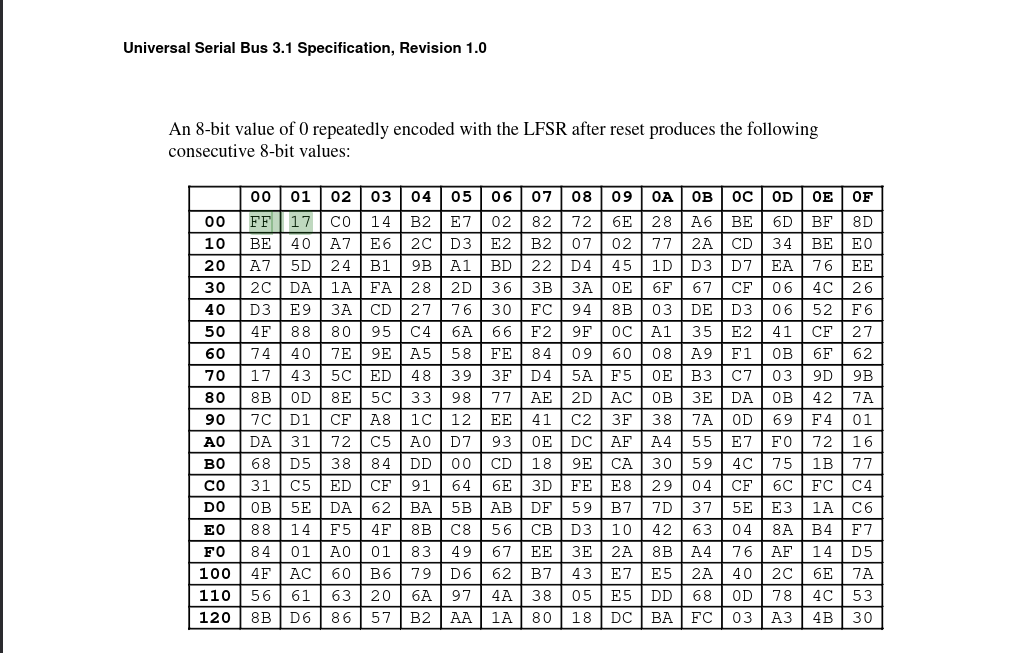
On retrouve avec cette sortie l’implémentation du scrambler (en C).
#include <stdio.h>
#include <stdlib.h>
static unsigned short lfsr = 0xffff; // 16 bit short for polynomial
int unscramble_byte(int inbyte)
{
static int descrambit[8];
static int bit[16];
static int bit_out[16];
int outbyte, i;
for (i=0; i<16;i++) // convert the LFSR to bit array for legibility
bit[i] = (lfsr >> i) & 1;
for (i=0; i<8; i++) // convert byte to be de-scrambled for legibility
descrambit[i] = (inbyte >> i) & 1;
// apply the xor to the data
descrambit[0] ^= bit[15];
descrambit[1] ^= bit[14];
descrambit[2] ^= bit[13];
descrambit[3] ^= bit[12];
descrambit[4] ^= bit[11];
descrambit[5] ^= bit[10];
descrambit[6] ^= bit[9];
descrambit[7] ^= bit[8];
// Now advance the LFSR 8 serial clocks
bit_out[ 0] = bit[ 8];
bit_out[ 1] = bit[ 9];
bit_out[ 2] = bit[10];
bit_out[ 3] = bit[11] ^ bit[ 8];
bit_out[ 4] = bit[12] ^ bit[ 9] ^ bit[ 8];
bit_out[ 5] = bit[13] ^ bit[10] ^ bit[ 9] ^ bit[ 8];
bit_out[ 6] = bit[14] ^ bit[11] ^ bit[10] ^ bit[ 9];
bit_out[ 7] = bit[15] ^ bit[12] ^ bit[11] ^ bit[10];
bit_out[ 8] = bit[ 0] ^ bit[13] ^ bit[12] ^ bit[11];
bit_out[ 9] = bit[ 1] ^ bit[14] ^ bit[13] ^ bit[12];
bit_out[10] = bit[ 2] ^ bit[15] ^ bit[14] ^ bit[13];
bit_out[11] = bit[ 3] ^ bit[15] ^ bit[14];
bit_out[12] = bit[ 4] ^ bit[15];
bit_out[13] = bit[ 5];
bit_out[14] = bit[ 6];
bit_out[15] = bit[ 7];
lfsr = 0;
for (i=0; i <16; i++) // convert the LFSR back to an integer
lfsr += (bit_out[i] << i);
outbyte = 0;
for (i= 0; i<8; i++) // convert data back to an integer
outbyte += (descrambit[i] << i);
return outbyte;
}
int main(){
for (int i = 0; i < 65535; i++)
{
printf("0x%x,", unscramble_byte(0));
}
}
On peut alors garder l’implémentation en C et l’utiliser sur nos octets en python, mais j’ai décidé de le réimplémenter rapidement en python histoire d’éviter que ce soit trop le bazar.
#scramble.py
lfsr = 0xffff
def reset_lsfr():
global lsfr
lfsr = 0xffff
def unscramble_byte(inbyte):
global lfsr
descrambit = [0] * 8
bit = [0] * 16
bit_out = [0] * 16
# Convert LFSR state to bit array
for i in range(16):
bit[i] = (lfsr >> i) & 1
# Convert input byte to bits
for i in range(8):
descrambit[i] = (inbyte >> i) & 1
# XOR descrambit with specific LFSR bits
for i in range(8):
descrambit[i] ^= bit[15 - i]
# Advance the LFSR 8 serial clocks
bit_out[0] = bit[8]
bit_out[1] = bit[9]
bit_out[2] = bit[10]
bit_out[3] = bit[11] ^ bit[8]
bit_out[4] = bit[12] ^ bit[9] ^ bit[8]
bit_out[5] = bit[13] ^ bit[10] ^ bit[9] ^ bit[8]
bit_out[6] = bit[14] ^ bit[11] ^ bit[10] ^ bit[9]
bit_out[7] = bit[15] ^ bit[12] ^ bit[11] ^ bit[10]
bit_out[8] = bit[0] ^ bit[13] ^ bit[12] ^ bit[11]
bit_out[9] = bit[1] ^ bit[14] ^ bit[13] ^ bit[12]
bit_out[10] = bit[2] ^ bit[15] ^ bit[14] ^ bit[13]
bit_out[11] = bit[3] ^ bit[15] ^ bit[14]
bit_out[12] = bit[4] ^ bit[15]
bit_out[13] = bit[5]
bit_out[14] = bit[6]
bit_out[15] = bit[7]
# Convert bit_out back to integer LFSR state
lfsr = 0
for i in range(16):
lfsr |= (bit_out[i] << i)
# Convert descrambit back to output byte
outbyte = 0
for i in range(8):
outbyte |= (descrambit[i] << i)
return outbyte
Un petit script pour tester notre générateur :
from scrambling import *
reset_lsfr()
print(" ".join(["{:02x}".format(unscramble_byte(0)) for _ in range(0x100)]))
On retrouve bien nos valeurs ff 17 c0 14 b2 e7 02 82 72 6e 28 a6 be 6d bf 8d be 40...
On va pouvoir implémenter ça :
from cntrl import flux
from scrambling import *
from colorama import Fore
table = {
0x1c : "SR",
0x3c : "CP",
0x5c : "SS",
0x7c : "BF",
0xbc : "BS",
0xf7 : "FE",
0xfb : "BE",
0xfd : "SE",
0xfe : "FS",
0x9c : "RESERVED",
0xDC : "RESERVED",
0xFC : "RESERVED",
}
Started = False
for i, (ctrl, byte) in enumerate(flux):
if(Started):
r = unscramble_byte(0)
if(ctrl):
if(table[byte] == "SR"):
Started = True
reset_lsfr()
if(Started):
print(Fore.RED, "\n",table[byte], Fore.RESET)
else:
if(Started):
print("{:02X}".format(byte^r),end=" ")
Comme le standard nous l’indique, on va commencer à partir d’un symbole “SR” qui indique qu’on réinitialise le registre LFSR à 0xffff. Ensuite, si c’est un octet de donnée (représenté en blanc ici) on va xorer l’octet généré par le LFSR avec l’octet.
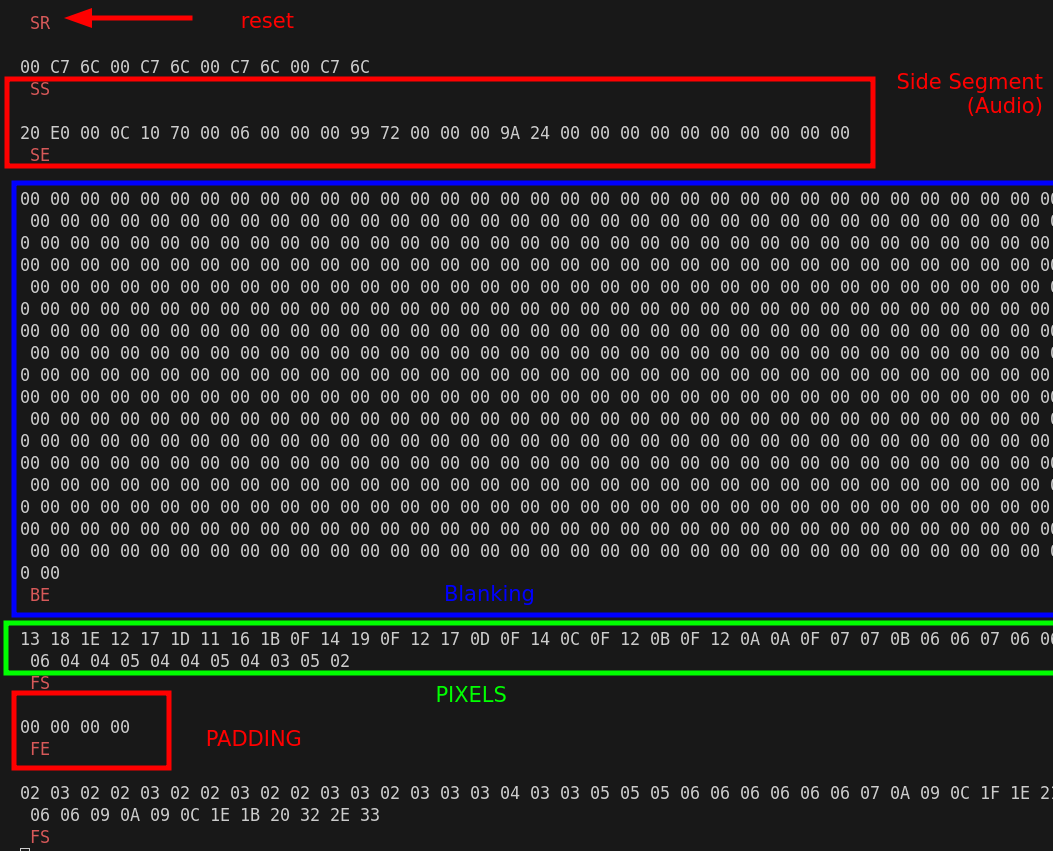
Là on peut être certain d’avoir des données correctes étant donné les “chunks” de 0 qui sont générés, on n’aurait pas ça si les données étaient incorrectes ou s’il y avait un décalage.
Retrouver notre image
Maintenant que nous pouvons lire des pixels, il ne reste plus rien pour retrouver notre image.
On va cependant devoir comprendre comment sont envoyés les pixels : sont-ils en ligne, en colonne, encore autrement ?
Dans cet exemple, on nous décrit les TU (transfert unit) comme l’ensemble “data + padding”, il a un “TU” d’une taille de 64 octets tandis que nous avons un “TU” de 62 octets.

On apprend également que les 0 sont invisibles, ils servent uniquement à faire une taille adaptée pour l’exigence du bitrate.
Donc il faut lire tous les octets en une seule ligne, on devrait avoir une taille de la dimension de notre écran en pixels (800) * 3 (RGB 24 bits).
Started = False
r = 0
dat_arr = []
recording = False
for i, (ctrl, byte) in enumerate(flux[0x171f:]):
if(Started):
r = unscramble_byte(0)
if(ctrl):
if(table[byte] == "SR"):
Started = True
reset_lsfr()
if(Started):
print(Fore.RED, "\n",table[byte], Fore.RESET)
if(table[byte] == "SS"):
recording = False
if(table[byte] == "BS"):
recording = False
if(dat_arr):
print(len(dat_arr))
exit(1)
if(table[byte] == "BE"):
recording = True
if(table[byte] == "FE"):
recording = True
if(table[byte] == "FS"):
recording = False
else:
if(Started):
if(recording):
print("{:02X}".format(byte^r),end=" ")
dat_arr.append(byte^r)

On a bien une taille de 2400 (800*3) ! Plus qu’à sauvegarder ces pixels dans un tableau et l’afficher ligne par ligne.
Voici le script pour décoder les pixels et les sauvegarder dans un tableau :
from cntrl import flux
from scrambling import *
from colorama import Fore
table = {
0x1c : "SR",
0x3c : "CP",
0x5c : "SS",
0x7c : "BF",
0xbc : "BS",
0xf7 : "FE",
0xfb : "BE",
0xfd : "SE",
0xfe : "FS",
0x9c : "RESERVED",
0xDC : "RESERVED",
0xFC : "RESERVED",
}
Started = False
ligne=0
r = 0
dat_arr = []
bigarr = []
recording = False
for i, (ctrl, byte) in enumerate(flux[0x171f:]): # direct sur le SR
if(Started):
r = unscramble_byte(0)
if(ctrl):
if(table[byte] == "SR"):
Started = True
reset_lsfr()
if(Started):
print(Fore.RED, "\n",table[byte], Fore.RESET)
if(table[byte] == "SS"):
recording = False
if(table[byte] == "BS"):
recording = False
if(dat_arr):
bigarr.append(dat_arr)
print("Added:", dat_arr, len(dat_arr))
dat_arr = []
if(len(bigarr) == 300):
with open("databarray.py", "w") as f:
f.write("bigarr = ")
f.write(str(bigarr))
exit(1)
if(table[byte] == "BE"):
recording = True
if(table[byte] == "FE"):
recording = True
if(table[byte] == "FS"):
recording = False
else:
if(Started):
if(recording):
print("{:02X}".format(byte^r),end=" ")
dat_arr.append(byte^r)
Voici le script pour traiter le tableau et le convertir en une image :
from PIL import Image
import numpy as np
from databarray import bigarr
def decode_dp_trames(trame_blocks, width, height):
flat = bytearray()
for blk in trame_blocks:
flat.extend(blk if isinstance(blk, (bytes, bytearray)) else bytes(blk))
needed = width * height * 3
pixel_data = flat[:needed]
arr = np.frombuffer(pixel_data, dtype=np.uint8).reshape((height, width, 3))
return Image.fromarray(arr, mode='RGB')
if __name__ == "__main__":
img = decode_dp_trames(bigarr, 800, 300)
img.save("output.png")
On a bien notre image finale !
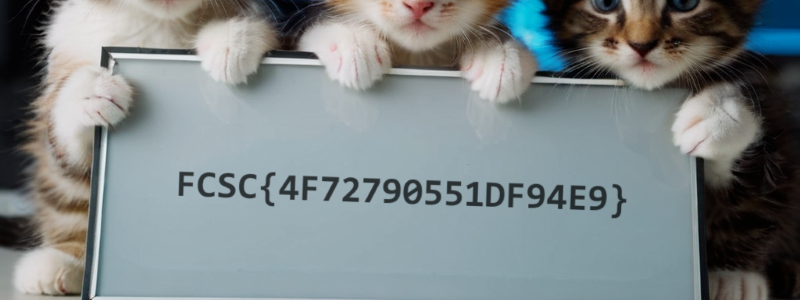
FLAG: FCSC{4F72790551DF94E9}
Conclusion
Challenge vraiment très rigolo à faire, j’avais très peu l’habitude de travailler avec des protocoles pour de la haute fréquence comme du Display Port.